Exploring Memtables
In the realm of high-performance database management systems, Log-Structured Merge (LSM) Trees have risen to prominence for their ability to efficiently manage vast amounts of data. One of the key components of an LSM tree is the Memtable. Memtables are dynamic in-memory data structures that serve as the initial touchpoint for engaging with the underlying database storage engine.
At the outset, the storage engine employs memtables to buffer all of the incoming write requests. As the write requests accumulate and the memtable buffers fill up, all of the data residing in the memtables undergoes conversion into a format suitable for disk storage. Subsequently, this transformed data is transferred to secondary storage, where it takes the form of Sorted String Tables (SSTables).
Because memtables exclusively contain all of the most recently written data, they participate in every read operation that the storage engine performs as well. Before examining any of the SSTables located on disk, the storage engine always attempts to extract data from the currently available memtables first. It only resorts to the SSTables when no data can be located in the memtables.
In today's article, we will implement a fully functional Memtable component as part of a simple key-value database storage engine. In the process, we will apply knowledge from one of our previous articles, "Implementing a Skip List in Go", so please make sure to review that article before continuing further in order to fully comprehend the topic that we are about to discuss.
Without further ado, let's get started!
Laying the Groundwork
Let's begin by outlining the main components of our storage engine, starting with the main Memtable struct. In most commercial databases (Apache Cassandra and CockroachDB, for example), memtables are typically built on top of skip lists. This choice is rooted in extensive benchmarking results, which consistently highlight that skiplist-based memtables provide good overall performance for both read and write operations regardless of whether sequential or random access patterns are used (a factor that will become more apparent later, when we discuss SSTables).
Consequently, we can just wrap the skip list that we developed in our prior article, "Implementing a Skip List in Go", into a new structure called Memtable. Since the only constraint to the growth of our memtable would be the total amount of RAM available on the machine, it might be a good idea to establish an upper limit to signal when a memtable should stop expanding and be replaced by another memtable. This will also impact the on-disk file size of the SSTables that are eventually going to be created on secondary storage.
For this reason, we specify two additional attributes in our Memtable struct called sizeUsed and sizeLimit. Our goal is to ensure that sizeUsed never goes beyond sizeLimit. If it is about to do so, we simply trigger the creation of a new memtable to prevent the old one from crossing the limit.
We define some additional methods to help us in achieving this requirement:
NewMemtable()to construct a new memtable initialized with an empty skip list and an externally specified size limit.HasRoomForWrite()to determine whether the memtable has adequate room for accommodating a specific key-value pair.Insert()to wrap the actual data insertion into the underlying skip list, while properly incrementing thesizeUsedcounter.
Thus, our initial memtable implementation reads:
type Memtable struct {
sl *skiplist.SkipList
sizeUsed int // The approximate amount of space used by the Memtable so far (in bytes).
sizeLimit int // The maximum allowed size of the Memtable (in bytes).
}
func NewMemtable(sizeLimit int) *Memtable {
m := &Memtable{
sl: skiplist.NewSkipList(),
sizeLimit: sizeLimit,
}
return m
}
func (m *Memtable) HasRoomForWrite(key, val []byte) bool {
sizeNeeded := len(key) + len(val)
sizeAvailable := m.sizeLimit - m.sizeUsed
if sizeNeeded > sizeAvailable {
return false
}
return true
}
func (m *Memtable) Insert(key, val []byte) {
m.sl.Insert(key, val)
m.sizeUsed += len(key) + len(val)
}memtable.go
Moving on, we also outline our main DB structure. This structure represents our database storage engine, exposing a public API for inserting, deleting, and retrieving data:
const (
memtableSizeLimit = 4 << 10 // 4 KiB
)
type DB struct {
memtables struct {
mutable *memtable.Memtable // the current mutable memtable
queue []*memtable.Memtable // all memtables that are not yet flushed to disk
}
}
func Open() *DB {
db := &DB{}
db.memtables.mutable = memtable.NewMemtable(memtableSizeLimit)
db.memtables.queue = append(db.memtables.queue, db.memtables.mutable)
return db
}
func (d *DB) Set(key, val []byte) {
// TODO: implement
}
func (d *DB) Get(key []byte) []byte {
// TODO: implement
return nil
}
func (d *DB) Delete(key []byte) {
// TODO: implement
}db.go
With both structures in place, we can continue working out the details of our implementation.
Inserting Data
To insert data, it is sufficient to instantiate a new DB struct and call its Set() method from our client code:
d := db.Open()
d.Set(key, val)main.go
The Open() method initializes the memtable component of our storage engine. As you might have noticed, the db.memtables field holds two sub-fields: mutable and queue. The mutable field points to the most recent memtable, which is also the only memtable capable of fulfilling write requests, while queue holds pointers to all of the memtables currently in existence.
Remember that as older memtables fill up, we replace them with newer ones. Each memtable sits patiently in the queue, waiting for its turn to be flushed to disk in the form of an SSTable. Only the mutable memtable, however, is not at capacity and has room for more writes. All other memtables are full and are therefore read-only.
This becomes more apparent as we complete the implementation of the Set() method and define its related helper method, rotateMemtables(), listed below:
func (d *DB) Set(key, val []byte) {
m := d.memtables.mutable
if !m.HasRoomForWrite(key, val) {
m = d.rotateMemtables()
}
m.Insert(key, val)
}
func (d *DB) rotateMemtables() *memtable.Memtable {
d.memtables.mutable = memtable.NewMemtable(memtableSizeLimit)
d.memtables.queue = append(d.memtables.queue, d.memtables.mutable)
return d.memtables.mutable
}db.go
This gives us a memtable component fully capable of handling data insertion and allows us to move on with our implementation.
Retrieving Data
The process of retrieving stored information involves traversing the memtable queue in reverse order (from the newest to the oldest memtable) in order to determine whether an item matching the provided search key is present in any of the underlying skip lists or not. If a match is identified, we stop looking through the remainder of the queue and simply return the value of the discovered data item.
The code below expresses this idea:
func (d *DB) Get(key []byte) ([]byte, error) {
// Scan memtables from newest to oldest.
for i := len(d.memtables.queue) - 1; i >= 0; i-- {
m := d.memtables.queue[i]
val, err := m.Get(key)
if err != nil {
continue // The only possible error is "key not found".
}
log.Printf(`Found key "%s" in memtable "%d" with value "%s"`, key, i, val)
return val, nil
}
return nil, errors.New("key not found")
}db.go
Since none of our earlier listings included the body of the Get() method from our Memtable struct, we are listing its implementation below:
func (m *Memtable) Get(key []byte) ([]byte, error) {
val, err := m.sl.Find(key)
if err != nil {
return nil, err
}
return val, nil
}memtable.go
As you can see, the Get() method simply searches the underlying skip list and returns the corresponding search result (if one is found).
We can then use the following code in our client in order to search for a specific key:
d := db.Open()
val, err := d.Get(key)
if err != nil {
fmt.Println("Key not found.")
} else {
fmt.Println(string(val))
}main.go
This code will look into all of the available memtables to find a particular key-value pair.
Introducing Tombstones
Everything seems great so far, but how do we handle deletions? Remember that only the mutable memtable is open for modification, and all other entries in the memtable queue are treated as read-only.
If a key resides in the mutable memtable, we could theoretically delete it by simply removing the corresponding data item from the underlying skip list. However, if the same key is duplicated in one of the earlier memtables, we will be out of luck, and further retrieval requests will continue producing results, returning the older value recorded for that key (the one residing in the older memtable).
This is where tombstones come into play. Essentially, a tombstone is a marker indicating that older data records corresponding to a given key should be shadowed due to a requested deletion. So, instead of removing any actual data from any underlying skip lists, we simply insert a special tombstone record into the latest memtable, thus shadowing all previous values for the provided key.
Having to support tombstone records means that we need a way to distinguish between regular insertions and tombstones. To do this, we can augment the format of our data records so that instead of storing a simple key-value pair, we also somehow include metadata indicating the type of the record. This can be accomplished by modifying the value component of each key-value pair.
We can embed the metadata directly into the value component by using the following encoding schema:
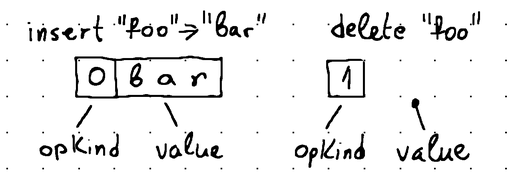
We can then introduce a new set of structures to encapsulate the encoding operations:
package encoder
type OpKind uint8
const (
OpKindDelete OpKind = iota
OpKindSet
)
type Encoder struct{}
func NewEncoder() *Encoder {
return &Encoder{}
}
func (e *Encoder) Encode(opKind OpKind, val []byte) []byte {
n := len(val)
buf := make([]byte, n+1)
buf[0] = byte(opKind)
copy(buf[1:], val)
return buf
}
func (e *Encoder) Parse(val []byte) *EncodedValue {
n := len(val)
buf := make([]byte, n-1)
opKind := val[0]
copy(buf, val[1:])
return &EncodedValue{val: buf, opKind: OpKind(opKind)}
}
type EncodedValue struct {
val []byte
opKind OpKind
}
func (ev *EncodedValue) Value() []byte {
return ev.val
}
func (ev *EncodedValue) IsTombstone() bool {
return ev.opKind == OpKindDelete
}
encoder.go
To make our memtables function with the new values of type EncodedValue rather than the simple []byte arrays that we used before, we have to apply the following changes:
type Memtable struct {
// ...
encoder *encoder.Encoder
}
func NewMemtable(sizeLimit int) *Memtable {
m := &Memtable{
// ...
encoder: encoder.NewEncoder(),
}
return m
}
func (m *Memtable) Insert(key, val []byte) {
m.sl.Insert(key, m.encoder.Encode(encoder.OpKindSet, val))
m.sizeUsed += len(key) + len(val) + 1
}
func (m *Memtable) InsertTombstone(key []byte) {
m.sl.Insert(key, m.encoder.Encode(encoder.OpKindDelete, nil))
m.sizeUsed += 1
}
func (m *Memtable) Get(key []byte) (*encoder.EncodedValue, error) {
val, err := m.sl.Find(key)
if err != nil {
return nil, err
}
return m.encoder.Parse(val), nil
}
memtable.go
We also have to modify the Get() method of our main DB structure, so that it starts recognizing tombstones:
func (d *DB) Get(key []byte) ([]byte, error) {
// Scan memtables from newest to oldest.
for i := len(d.memtables.queue) - 1; i >= 0; i-- {
m := d.memtables.queue[i]
encodedValue, err := m.Get(key)
if err != nil {
continue // The only possible error is "key not found".
}
if encodedValue.IsTombstone() {
log.Printf(`Found key "%s" marked as deleted in memtable "%d".`, key, i)
return nil, errors.New("key not found")
}
log.Printf(`Found key "%s" in memtable "%d" with value "%s"`, key, i, encodedValue.Value())
return encodedValue.Value(), nil
}
}db.go
As you can see, the Get() method will state that a key is not found when, in fact, the key is present, but a tombstone shadows its prior values.
The Delete() method then becomes almost identical to the Insert() method, the only difference being that we call m.InsertTombstone(key) instead of m.Insert(key, val):
func (d *DB) Delete(key []byte) bool {
m := d.memtables.mutable
if !m.HasRoomForWrite(key, nil) {
m = d.rotateMemtables()
}
m.InsertTombstone(key)
}db.go
To get rid of any repeating code, we can narrow this down to:
func (d *DB) Set(key, val []byte) {
m := d.prepMemtableForKV(key, val)
m.Insert(key, val)
}
func (d *DB) Delete(key []byte) {
m := d.prepMemtableForKV(key, nil)
m.InsertTombstone(key)
}
// Ensures that the mutable memtable has sufficient space
// to accommodate the insertion of "key" and "val".
func (d *DB) prepMemtableForKV(key, val []byte) *memtable.Memtable {
m := d.memtables.mutable
if !m.HasRoomForWrite(key, val) {
m = d.rotateMemtables()
}
return m
}db.go
With that, we have fully working deletion using tombstones to shadow old records.
Flushing Memtables to Disk
Even with generous amounts of RAM available, we cannot store an unlimited amount of memtables in our memtable queue. At some point, we have to persist the accumulated data on disk to both keep the memory usage under control and, more importantly, to allow our data to survive through server restarts. This process is known as flushing.
When performing a flush, we traverse all of the read-only memtables residing in the memtable queue, starting from the oldest one and moving towards the newest. We don't touch the mutable memtable. During the traversal, we transform the data into a format that's more suitable for on-disk storage. Ultimately, the converted data is saved on disk in the form of SSTable files (binary files with an *.sst extension).
We will only briefly touch on the intricacies of SSTables in today's article, but we can say that SSTables use a structured binary format that maintains persisted data in sorted order, while facilitating quick and efficient searching.
We can initiate a flush when a specific threshold is exceeded. For instance, we can specify that if the combined size of all of the memtables exceeds a particular threshold in bytes, the data in all of the read-only memtables should be flushed to disk. Then, each time a new record is added to a memtable, we can compare the overall size of all existing memtables against this defined threshold and trigger a flush if necessary.
We can use the following code to express this intention:
const (
// ...
memtableFlushThreshold = 8 << 10 // 8 KiB
)
// ...
func (d *DB) Set(key, val []byte) {
// ...
d.maybeScheduleFlush()
}
func (d *DB) Delete(key []byte) {
// ...
d.maybeScheduleFlush()
}
// ...
func (d *DB) maybeScheduleFlush() {
var totalSize int
for i := 0; i < len(d.memtables.queue); i++ {
totalSize += d.memtables.queue[i].Size()
}
if totalSize <= memtableFlushThreshold {
return
}
err := d.flushMemtables()
if err != nil {
log.Fatal(err)
}
}
func (d *DB) flushMemtables() error {
// TODO: implement
return nil
}db.go
This calls for a small change in our Memtable struct, namely the inclusion of a new method that makes it possible to obtain information about the current memtable size:
func (m *Memtable) Size() int {
return m.sizeUsed
}memtable.go
You may have noticed in the listing above that the body of the flushMemtables() method, which performs the actual work, has been purposefully left empty. This is because we need to clarify a couple of things. First, we need to figure out how to scan our memtables sequentially. Second, we need to agree on the precise data format to use for building our SSTables.
The name SSTable stands for Sorted String Table and implies that data within an *.sst file is stored sorted by key in ascending order. The skip lists that our memtables are based upon already maintain their data sorted in ascending order, so converting their data to the agreed-upon SST data format while maintaining the correct order is a relatively simple task, assuming that we have a mechanism in place that allows us to scan the skip lists sequentially.
Unfortunately, the skip list implementation that we discussed in the original "Implementing a Skip List in Go" article doesn't provide such mechanism, so we have to implement it. Knowing the fact that, by definition, the very first level of a skip list (Level 0) contains all of its items makes the implementation quite straightforward—to scan the list sequentially, we just need to iterate its first level.
Taking inspiration from the Iterator interface in Java, we end up with the following implementation:
package skiplist
type Iterator struct {
current *node
}
func (sl *SkipList) Iterator() *Iterator {
return &Iterator{sl.head}
}
func (i *Iterator) HasNext() bool {
return i.current.tower[0] != nil
}
func (i *Iterator) Next() ([]byte, []byte) {
i.current = i.current.tower[0]
if i.current == nil {
return nil, nil
}
return i.current.key, i.current.val
}
iterator.go
In addition to that, we define a new method in our Memtable struct that enables us to instantiate new iterators:
func (m *Memtable) Iterator() *skiplist.Iterator {
return m.sl.Iterator()
}memtable.go
Using this method, we can now scan any memtable sequentially in the following way:
i := m.Iterator()
for i.HasNext() {
key, val := i.Next()
// do something with "key" and "val".
}With the sequential scanning mechanism in place, the only thing left to address is the data format we'll employ for on-disk data storage.
Writing SSTables
We would like to keep this article focused on memtables. With that in mind, we are going to employ a very basic data format for our SSTables. Each *.sst file will be a simple sequence of data blocks. Each data block represents a specific key-value pair and has the following structure:
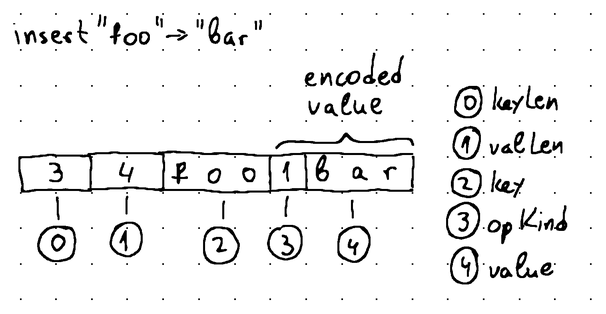

To encapsulate the logic for transforming a memtable into an SSTable and persist everything on disk, we introduce a new struct called sstable.Writerexporting the following methods:
NewWriter()for constructing a newsstable.Writerinstance, accepting a writable file descriptor that's wrapped for performing buffered I/O in 4 KiB data blocks.Process()for iterating a memtable sequentially and converting its data to SSTable data blocks (using thewriteDataBlock()method, which performs the actual encoding).Close()for flushing any remaining data from the data buffers and forcing the kernel to persist all changes to disk before closing the open file handles.
The full code reads:
package sstable
import (
// ...
)
type syncCloser interface {
io.Closer
Sync() error
}
type Writer struct {
file syncCloser
bw *bufio.Writer
buf []byte
}
func NewWriter(file io.Writer) *Writer {
w := &Writer{}
bw := bufio.NewWriter(file)
w.file, w.bw = file.(syncCloser), bw
w.buf = make([]byte, 0, 1024)
return w
}
func (w *Writer) Process(m *memtable.Memtable) error {
i := m.Iterator()
for i.HasNext() {
key, val := i.Next()
err := w.writeDataBlock(key, val)
if err != nil {
return err
}
}
return nil
}
func (w *Writer) writeDataBlock(key, val []byte) error {
keyLen, valLen := len(key), len(val)
needed := 4 + keyLen + valLen
buf := w.buf[:needed]
binary.LittleEndian.PutUint16(buf[:], uint16(keyLen))
binary.LittleEndian.PutUint16(buf[2:], uint16(valLen))
copy(buf[4:], key)
copy(buf[4+keyLen:], val)
bytesWritten, err := w.bw.Write(buf)
if err != nil {
log.Fatal(err, bytesWritten)
return err
}
return nil
}
func (w *Writer) Close() error {
// Flush any remaining data from the buffer.
err := w.bw.Flush()
if err != nil {
return err
}
// Force OS to flush its I/O buffers and write data to disk.
err = w.file.Sync()
if err != nil {
return err
}
// Close the file.
err = w.file.Close()
if err != nil {
return err
}
w.bw = nil
w.file = nil
return err
}
writer.go
We are now almost ready to implement our db.flushMemtables() method. The only thing left to solve beforehand is to abstract our data storage.
Abstracting the Data Storage
Our sstable.Writer is engineered to work with any abstraction satisfying the io.Writer interface. However, to this point, we haven't produced any code for actually creating, writing, or reading files in the filesystem, and we really need this to be able to complete our implementation.
For that purpose, we introduce another new structure named storage.Provider. The storage.Provider manages the primary data folder of our storage engine. This folder contains all of the *.sst files produced during the lifespan of our database. Upon startup, the storage.Provider ensures that this folder exists and is accessible for reading and writing.
The storage.Provider also provides methods for preparing and opening new files for writing, listing available files, and opening existing files for reading. Instead of working with raw os.File file descriptors, it introduces a lightweight FileMetadata data structure that abstracts away low-level information and only reports a number uniquely identifying the particular file inside the data folder managed by the storage.Provider, as well as its file type (this allows us to skip non-SST files if we discover any in the data folder).
To be able to generate file numbers, the storage.Provider maintains a global fileNum counter, ensuring that each subsequently generated *.sst file gets a unique identifier.
The complete implementation looks like this (it is a bit long, but hopefully clear enough):
package storage
import (
"fmt"
"os"
"path/filepath"
)
type Provider struct {
dataDir string
fileNum int
}
type FileType int
const (
FileTypeUnknown FileType = iota
FileTypeSSTable
)
type FileMetadata struct {
fileNum int
fileType FileType
}
func (f *FileMetadata) IsSSTable() bool {
return f.fileType == FileTypeSSTable
}
func (f *FileMetadata) FileNum() int {
return f.fileNum
}
func NewProvider(dataDir string) (*Provider, error) {
s := &Provider{dataDir: dataDir}
err := s.ensureDataDirExists()
if err != nil {
return nil, err
}
return s, nil
}
func (s *Provider) ensureDataDirExists() error {
err := os.MkdirAll(s.dataDir, 0755)
if err != nil {
return err
}
return nil
}
func (s *Provider) ListFiles() ([]*FileMetadata, error) {
files, err := os.ReadDir(s.dataDir)
if err != nil {
return nil, err
}
var meta []*FileMetadata
var fileNumber int
var fileExtension string
for _, f := range files {
_, err = fmt.Sscanf(f.Name(), "%06d.%s", &fileNumber, &fileExtension)
if err != nil {
return nil, err
}
fileType := FileTypeUnknown
if fileExtension == "sst" {
fileType = FileTypeSSTable
}
meta = append(meta, &FileMetadata{
fileNum: fileNumber,
fileType: fileType,
})
}
return meta, nil
}
func (s *Provider) nextFileNum() int {
s.fileNum++
return s.fileNum
}
func (s *Provider) makeFileName(fileNumber int) string {
return fmt.Sprintf("%06d.sst", fileNumber)
}
func (s *Provider) PrepareNewFile() *FileMetadata {
return &FileMetadata{
fileNum: s.nextFileNum(),
fileType: FileTypeSSTable,
}
}
func (s *Provider) OpenFileForWriting(meta *FileMetadata) (*os.File, error) {
const openFlags = os.O_RDWR | os.O_CREATE | os.O_EXCL
filename := s.makeFileName(meta.fileNum)
file, err := os.OpenFile(filepath.Join(s.dataDir, filename), openFlags, 0644)
if err != nil {
return nil, err
}
return file, nil
}
func (s *Provider) OpenFileForReading(meta *FileMetadata) (*os.File, error) {
const openFlags = os.O_RDONLY
filename := s.makeFileName(meta.fileNum)
file, err := os.OpenFile(filepath.Join(s.dataDir, filename), openFlags, 0)
if err != nil {
return nil, err
}
return file, nil
}
provider.go
To integrate the newly introduced storage.Provider with our main DB structure, we have to apply some small changes:
type DB struct {
dataStorage *storage.Provider
// ...
}
func Open(dirname string) (*DB, error) {
dataStorage, err := storage.NewProvider(dirname)
if err != nil {
return nil, err
}
db := &DB{dataStorage: dataStorage}
// ...
return db, nil
}db.go
This also alters the way we initialize our storage engine in our client code; we now have to pass a folder name to the Open() method:
const dataFolder = "demo"
d, err := db.Open(dataFolder)
if err != nil {
log.Fatal(err)
}main.go
With the sstable.Writer and storage.Provider finalized, we can finally implement the db.flushMemtables() method:
func (d *DB) flushMemtables() error {
n := len(d.memtables.queue) - 1
flushable := d.memtables.queue[:n]
d.memtables.queue = d.memtables.queue[n:]
for i := 0; i < len(flushable); i++ {
meta := d.dataStorage.PrepareNewFile()
f, err := d.dataStorage.OpenFileForWriting(meta)
if err != nil {
return err
}
w := sstable.NewWriter(f)
err = w.Process(flushable[i])
if err != nil {
return err
}
err = w.Close()
if err != nil {
return err
}
}
return nil
}db.go
The method iterates all of the read-only memtables, prepares new *.sst files on disk for each individual memtable, and then fills each file with content.
Searching SSTables
Now that we are successfully writing SSTables to disk, we need to have them included in the search pipeline. Otherwise, we won't be able to look up data that is persisted on disk. For that purpose, we can introduce a new field in our main DB structure named sstables, which can be used for storing references to all SSTables available on disk. By slightly modifying the flushMemtables() method that we just finished implementing, we can ensure that the newly introduced sstables field is always kept up to date with metadata identifying each newly created SSTable:
type DB struct {
// ...
sstables []*storage.FileMetadata
}
func (d *DB) flushMemtables() error {
// ...
for i := 0; i < len(flushable); i++ {
// ...
d.sstables = append(d.sstables, meta)
}
return nil
}db.go
This allows us to introduce an sstable.Reader that lets us search SSTables for specific keys. The sstable.Reader simply iterates the data blocks of any loaded *.sst file and tries to find matches for a particular key. The implementation is quite straightforward:
package sstable
import (
// ...
)
var ErrKeyNotFound = errors.New("key not found")
type Reader struct {
file io.Closer
br *bufio.Reader
buf []byte
encoder *encoder.Encoder
}
func NewReader(file io.Reader) *Reader {
r := &Reader{}
r.file, _ = file.(io.Closer)
r.br = bufio.NewReader(file)
r.buf = make([]byte, 0, 1024)
return r
}
func (r *Reader) Get(searchKey []byte) (*encoder.EncodedValue, error) {
for {
buf := r.buf[:4]
_, err := io.ReadFull(r.br, buf)
if err != nil {
if err == io.EOF {
break
}
return nil, err
}
keyLen := binary.LittleEndian.Uint16(buf[:2])
valLen := binary.LittleEndian.Uint16(buf[2:])
needed := keyLen + valLen
buf = r.buf[:needed]
_, err = io.ReadFull(r.br, buf)
if err != nil {
return nil, err
}
key := buf[:keyLen]
val := buf[keyLen:]
if bytes.Compare(searchKey, key) == 0 {
return r.encoder.Parse(val), nil
}
}
return nil, ErrKeyNotFound
}
func (r *Reader) Close() error {
err := r.file.Close()
if err != nil {
return err
}
r.file = nil
r.br = nil
return nil
}
reader.go
We then need to adapt our Get() method for scanning the SSTables right after it has finished searching all memtables without finding a matching result:
func (d *DB) Get(key []byte) ([]byte, error) {
// Scan memtables from newest to oldest.
for i := len(d.memtables.queue) - 1; i >= 0; i-- {
// ...
}
// Scan sstables from newest to oldest.
for j := len(d.sstables) - 1; j >= 0; j-- {
meta := d.sstables[j]
f, err := d.dataStorage.OpenFileForReading(meta)
if err != nil {
return nil, err
}
r := sstable.NewReader(f)
defer r.Close()
var encodedValue *encoder.EncodedValue
encodedValue, err = r.Get(key)
if err != nil {
if errors.Is(err, sstable.ErrKeyNotFound) {
continue
}
log.Fatal(err)
}
if encodedValue.IsTombstone() {
log.Printf(`Found key "%s" marked as deleted in sstable "%d".`, key, meta.FileNum())
return nil, errors.New("key not found")
}
log.Printf(`Found key "%s" in sstable "%d" with value "%s"`, key, meta.FileNum(), encodedValue.Value())
return encodedValue.Value(), nil
}
return nil, errors.New("key not found")
}db.go
Our search procedure is now complete and works with both memtables and sstables.
Restoring the Database State
With the code that we have so far, you may observe that after restarting our database storage engine, data previously stored on disk becomes inaccessible. This is due to the fact that the db.sstables field is only being populated by the flushMemtables() procedure.
To address this issue, we simply need to scan the data folder after every restart and populate the db.sstables field with the metadata retrieved from the data folder. We can do this by introducing the method loadSSTables() and slightly modifying our db.Open() method as follows:
func Open(dirname string) (*DB, error) {
dataStorage, err := storage.NewProvider(dirname)
if err != nil {
return nil, err
}
db := &DB{dataStorage: dataStorage}
err = db.loadSSTables()
if err != nil {
return nil, err
}
db.memtables.mutable = memtable.NewMemtable(memtableSizeLimit)
db.memtables.queue = append(db.memtables.queue, db.memtables.mutable)
return db, nil
}
func (d *DB) loadSSTables() error {
meta, err := d.dataStorage.ListFiles()
if err != nil {
return err
}
for _, f := range meta {
if !f.IsSSTable() {
continue
}
d.sstables = append(d.sstables, f)
}
return nil
}db.go
Now, every time we restart our storage engine, we will still be able to access the data stored in its *.sst files.
Final Words
We've covered a lot of ground, and as always you can find the full source code for this tutorial over here:
 cloudcentricdev
cloudcentricdevYet there is so much more ground to cover and crucial questions to be answered:
Q: What happens to the data stored in the unflushed memtables if we abruptly terminate the database storage engine process?
A: We will unfortunately lose all of this data and currently have no recovery mechanism in place. We can resolve this by implementing a write-ahead log (WAL). We will cover this in a follow-up article, so stay tuned!
Q: What methods can we employ to optimize the search process within our SSTables and minimize their footprint on disk?
A: We traded off performance for simplicity. The sequential search that we are currently doing is far from ideal. We are also wasting a lot of disk space due to our inefficient data format. We will address all of this issues in a follow-up article specifically focused on SSTables. Stay tuned!
I hope you found some valuable information in this article. Please don't hesitate to get in touch if you have any questions or comments.
Until then, feel welcome to play around with the provided CLI:
References
I drew most of my inspiration for this article from tinkering with the Pebble storage engine created by Cockroach Labs.
You can find its source code at https://github.com/cockroachdb/pebble.