Protecting Docker with User Namespaces
In today's article, we are going to discuss the benefits of using user namespaces for securing our Docker environments. The official Docker documentation contains a page explaining how to isolate containers with a user namespace in order to prevent potential privilege-escalation attacks, and even though the instructions on that page are fairly detailed, I still feel it's not entirely apparent what user namespaces can protect you from exactly, especially if you haven't used them before.
My goal here is to make this clear through a practical example, and hopefully this will solidify your understanding of user namespaces, how they work, and why it's important to have them properly configured in a Docker environment.
Without further ado, let's go ahead and dive into our example.
Exploring a usual Docker setup
Let's imagine a typical scenario: engineers from different teams at your organization share a virtual private server to run Docker containers in a collaborative environment. Each engineer has a dedicated user account on the server, and for convenience, every account has been added to the docker group, allowing users to issue docker commands without having to prefix them with sudo.
Docker runs with its default configuration, so there's no user namespace isolation enabled, and the dockerd daemon runs as root. No user besides the main system administrator has sudo access on the server, and to the casual observer, the system appears relatively secure in terms of user privileges and access control.
Everything runs smoothly, until one day a malicious actor manages to gain access to a user account on the server. In this case, unless Docker containers are protected with a user namespace, the attacker can easily infiltrate other user accounts on the server by exploiting the default Docker configuration.
Exploiting the default Docker configuration
To understand why exploiting the default Docker configuration is possible, let's recap how Docker launches containers in the first place.
Suppose you issue a command such as:
docker run --rm hello-worldWhen you do that, you are not really launching the container on behalf of your user ID. You are actually making use of the Docker client to tell the Docker daemon running in the background to launch a new container for you. We won't delve further into the mechanics of how this happens precisely, but the main point is that the docker command doesn't launch the container. It only expresses the intention, and then it's dockerd that organizes the actual launch:
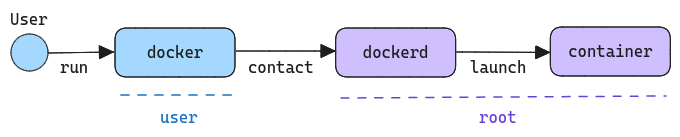
Because the dockerd daemon runs as root by default, any containers that it launches can also execute commands as root (technically, dockerd relies on another daemon called containerd to setup the container, but it also runs as root, so you get the point).
You can verify this by running:
ps -f -p $(pgrep 'dockerd|containerd')Both daemons run as root:
UID PID PPID C STIME TTY STAT TIME CMD
root 1945 1 0 10:01 ? Ssl 0:03 /usr/bin/containerd
root 2704 1 0 10:01 ? Ssl 0:17 /usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sockAt the same time, adding users to the docker group allows them to issue docker commands without having root privileges because the Docker client and the Docker daemon communicate through a Unix socket, which is configured to provide read/write permissions to all users in the docker group.
You can verify this by running:
ls -l /var/run/docker.sockThe output confirms that all members of the docker group can read and write to the socket:
srw-rw---- 1 root docker 0 Dec 14 11:19 /var/run/docker.sockEssentially, this allows any user in the docker group to exploit the system and escape the confinement of a container, gaining full root access to the host.
It's as easy as running:
docker run -v /:/host --rm -it alpine chroot /host shThe command starts a new Docker container from the Alpine image and drops the attacker into a root shell, allowing them to perform any changes they want to the underlying system.
For example, there's nothing stopping the attacker from modifying the user account files (e.g. /etc/passwd, /etc/shadow, and so on) in /etc. We can prove this by creating a new file inside /etc:
touch /etc/test.txtInstead of seeing a permission error, the new file is created successfully, despite the fact that the folder is owned by root on the host and not by the user who started the container (who, as you remember, didn't have any root permissions on the host).
Performing an ls both inside and outside of the container further confirms this:
ls -l /etc/test.txtIn both cases, root appears as the file owner:
-rw-r--r-- 1 root root 0 Dec 14 14:46 /etc/test.txtSince we issued chroot /host sh, which effectively started a new shell session, you can verify that the shell open inside the Alpine container runs as root by typing:
ps -f -p $(pidof sh)The output states:
UID PID PPID C STIME TTY STAT TIME CMD
root 242796 242774 0 14:48 pts/0 Ss+ 0:00 shSo even though the user who executed the original docker command was neither root nor a member of the sudo group on the server, they were still able to gain full root access to the underlying system and create a file in a folder that they weren't supposed to have access to.
Protecting Docker with User Namespaces
The previously described scenario would not have been possible if user namespaces were utilized. With user namespaces, you can instruct Docker to map the root user inside the container to a non-privileged user on the host system. So while the processes still appear to be running as root inside the container, they actually use a completely different user ID on the host.
Anyone with root access to the server can enable this feature by making a small adjustment to the Docker daemon configuration file. On Linux, this file is usually located at /etc/docker/daemon.json (if the file doesn't exist, it's safe to create it and Docker will pick it up automatically on the next restart).
Add the following instruction to daemon.json:
{
"userns-remap": "default"
}Then restart the Docker daemon:
systemctl restart dockerSeveral things happen as a result. First, Docker creates a new user and group on the system, both named dockremap.
To verify this, run:
id dockremapuid=110(dockremap) gid=117(dockremap) groups=117(dockremap)Additionally, Docker adds an entry for dockremap in both the /etc/subuid and /etc/subgid files on the host system:
grep dockremap /etc/subuiddockremap:165536:65536grep dockremap /etc/subgiddockremap:165536:65536On Linux, the files /etc/subuid and /etc/subgid are used for configuring subordinate user and group ID ranges for user namespaces. The expression dockremap:165536:65536 basically means that the user account dockremap is allocated a subordinate user ID range of 65536 total IDs, starting at 165536 and ending at 231071 (165536+65536-1).
This means that Docker can now map the root user ID inside the container to the very first ID from the dockremap subordinate range (i.e., 165536).
To see this in action, run the same command:
docker run -v /:/host --rm -it alpine chroot /host shThen try touching the test.txt file once again:
touch /etc/test.txtThis time, the output says:
touch: cannot touch '/etc/test.txt': Permission deniedThat's because user namespace isolation is enabled.
Run the following command:
ls -l / | grep etcYou will notice that the /etc folder appears to be owned by nobody:nogroup inside the container:
drwxr-xr-x 102 nobody nogroup 4096 Dec 14 12:39 etcOn the host, however, the owner is root:root:
drwxr-xr-x 102 root root 4096 Dec 14 12:39 etcThis is because any user or group ID not explicitly mapped to the user namespace is reported as nobody (respectively, nogroup) inside that namespace.
You can see the user namespace mapping by running the following command inside the container:
cat /proc/self/uid_mapThe output indicates that user ID 0 (i.e., root) in the current user namespace maps to user ID 165536 on the host. This mapping continues for all subsequent 65536 user IDs (so 1 in the container maps to 165537 on the host, 2 in the container maps to 165538 on the host, and so on):
0 165536 65536If the container was running without user namespace mapping, cat /proc/self/uid_map would have reported this instead:
0 0 4294967295Let's try something else and create a file inside the /tmp folder from within the container (remember that on Linux the /tmp folder is world-writable):
touch /tmp/test.txtNow run an ls inside the container:
ls -l /tmp/test.txt From the output, it appears that the file is owned by root:
-rw-r--r-- 1 root root 0 Dec 14 13:30 /tmp/test.txtRun the same command on the host itself:
ls -l /tmp/test.txt This time, you will see that the file actually belongs to user 165536 on the host:
-rw-r--r-- 1 165536 165536 0 Dec 14 13:30 /tmp/test.txtIn other words, the root user inside the container (ID 0) actually corresponds to user ID 165536 on the host.
With the container still running, try executing the following command on the host:
ps -f -p $(pidof sh)You will see that the sh process running inside the container runs as user 165536 on the host, which further confirms that the user namespace mapping works:
UID PID PPID C STIME TTY TIME CMD
165536 4064 4046 0 12:43 pts/0 00:00:00 sh
With that, we can conclude our exploration of user namespaces.
Final thoughts
User namespaces provide an effective mechanism to manage and secure user privileges within running containers. By mapping user IDs from the container to different user IDs on the host, we can ensure that processes inside the container cannot access resources or perform actions outside their defined boundaries.
This adds an extra layer of security and allows for better management of user permissions in containerized environments, making user namespace isolation a valuable mechanism for protecting system integrity and ensuring that containerized applications are securely isolated from the host.
I hope this article has provided a clear understanding of the importance of user namespace isolation in containerized environments. Thanks for reading, and until next time!